
Sztuczna inteligencja w ostatnim czasie poszła bardzo do przodu – a przynajmniej niektóre z jej gałęzi związane z NLP (natural language processing) dzięki teraflopom danych przetworzonych przez Google (openai). Ten artykuł jednak nie będzie mówił czy uczył o tym jak napisać takie super narzędzie (fizycznie samodzielnie mało kto jest do tego zdolny i mało kto posiada moc obliczeniową na to pozwalającą.
TL;DR
W artykule nie omawiam podstaw tego jak sieci neuronowe działają ani dlaczego są takie fajnie :D. Kwestie oczywiste takie jak trening nadzorowany i nienadzorowany Raczej przedstawiam bibliotekę i odpowiadam na pytanie „czy można?”. Można, dość prosto robi się to przy użyciu Deep Java Library do czego zachęcam. A po co? Jest kilka powodów – elegancja, brak chęci mieszania różnych technologii, oszczędność na utrzymaniu i integracji a na końcu – szybkość – choć finalnie jest to dyskusyjne i w zależnosci od silnika może nie być tak mocnym argumentem. Niżej znajdziecie krótki exec/+kod jednego z exampli dostępnych w repozytorium djl oraz model dla problemu klasyfikacji Irysów.
Popularne AI
W sektorze AI wiodącym językiem jest Python. Jest to powodowane głównie przez to, że to dla niego (jako pierwszego „w miarę” cywilizowanego, prostego języka) powstała masa przeróżnych bibliotek pozwalających na wykonywanie obliczeń i transformacji w przestrzeniach opartych o wektory i wiele wymiarów (a także bibliotek AI–CUDA dla operacji na silnikach graficznych). I nawet mimo, że Python jest językiem wolnym, to implementacje tych bibliotek korzystają natywnie z zależności napisanych w C i C++ które mają pod spodem. Dzięki temu mimo wszystko wykonywanie skomplikowanych operacji macierzowych czy wektorowych nie jest ani mozolnie trudne ani długotrwałe. Ma to jednak swoje minusy – np. przenaszalność. Python mimo bycia językiem dostępnym na każdą platformę i uniwersalnym, w kwestii bibliotek obliczeniowych i AI już tak uniwersalny nie jest – przekona się o tym każdy, kto spróbuje uruchomić zdockeryzowanego job-a pysparkowego na masterze/workerze w chmurze stojącej na maszynie o innej kompilacji bibliotek wymaganych chociażby przez bibliotekę numpy (podstawową bibliotekę pythona do operacji wektorowych i macierzowych). Finałem może być nawet segmentation fault. Oczywiście jest to pojedynczy przypadek, gdzie taka sytuacja ma miejsce, ale generalnie współpraca pythona ze Sparkiem w środowisku chmurowym (a przecież tego wszyscy chyba chcemy?) potrafi mocno dać w kość (chociażby przez problemy z symbolami NaN, Inf+, Inf- i ich przetwarzaniem przez język Scala, w którym Spark jest napisany). To mimo wszystko są zbyt słabe argumenty aby Python mający biblioteki takie jak PyTorch czy Keras i Tensorflow został zdetronizowany wśród „AI”-owej społeczności.
Choć faktem jest, że duże firmy oprócz pythona używają też zaawansowanych algorytmów w językach szybszych takich jak C czy C++, to przeciętny Geek z zajawką na AI odpala pythona na Anaconda na swoim macu czy windowsie, otwiera okienko Jupyter Notebooka i zaczyna składać bezładnie kolejne komendy, których nie rozumie 😀 (nikt na początku nie rozumie o co chodzi, chyba że wcześniej był matematykiem xD). Najgorzej, kiedy zaczynasz swoją przygodę z AI a nie jesteś ani matematykiem ani programistą – wtedy popełnisz na swojej ścieżce prawdopodobnie wszystkie możliwe do popełnienia błędy (a tych jest sporo).
AI dla Javowców
Do tego momentu powinienem zostać już kilkukrotnie przeklęty i biczowany przez ludzi interesujących się tematem, między innymi za to, że nie wspomniałem o bibliotece SparkML, którą można wykorzystywać z powodzeniem zarówno przy użyciu języka python jak i Java. Została ona pominięta umyślnie z jednego powodu – wykorzystywane w niej algorytmy nie są sieciami neuronowymi. To oznacza, że każdy model biblioteki SparkML jest modelem matematycznym (statystycznym) i znając wartości początkowe algorytmu oraz rozkład danych wejściowych jesteśmy w stanie (w teorii nawet przy użyciu kartki i długopisu) odwzorować cały proces działania algorytmu aż do uzyskania wyniku. Sieci neuronowe natomiast choć ich teoria jest ściśle matematyczna to proces ich uczenia i później „rozumowania” jest wypadkową wielu różnych skomplikowanych operacji, których ręczne odtworzenie człowiekowi zajęło by zbyt wiele czasu (jest zbyt wiele zmiennych które zbyt często zmieniają się w sposób zbyt losowy).
Jeśli jesteście zainteresowani rozwiązaniem prostych problemów klasyfikacji (do jakiej klasy należy „obiekt” na podstawie jego mierzalnych cech „fizycznych”) zachęcam do zapoznania się z biblioteką SparkML dostępną tutaj.
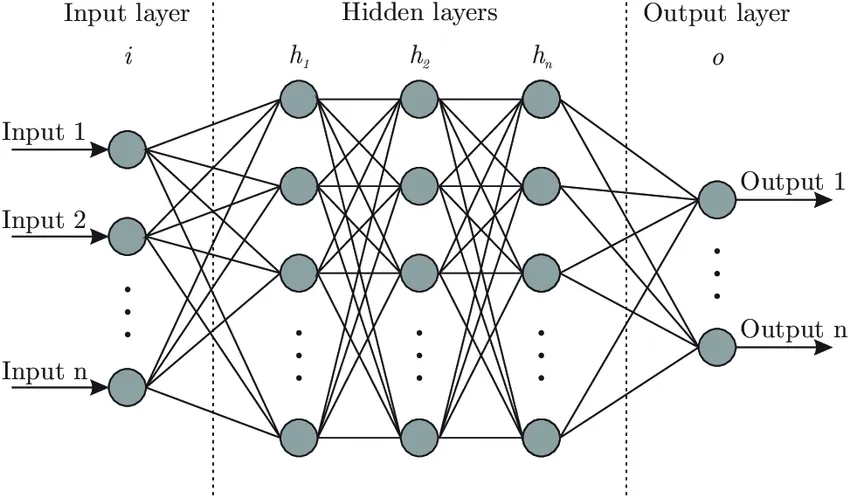
Do czego można więc zastosować sieci neuronowe? Choć z doświadczenia powinienem powiedzieć „zazwyczaj do niczego bo SVM albo regresja działają prawie tak samo dobrze”, to nie byłaby to prawda w co najmniej dwóch przypadkach:
- Rozpoznawanie i generowanie obrazu,
- Rozpoznawanie tekstu i (ostatnio popularne) chatboty.
Dodatkowo to, co odróżnia sieci neuronowe i różne rodzaje „learningu” od modeli statystycznych, to fakt ich właściwie nieskończonych możliwości samodoskonalenia i radzenia sobie z różnymi problemami (przynajmniej w teorii). Sprawdźmy więc jeden z najbardziej popularnych przykładów (zbiór cyfr pisanych ręcznie ze zbiorów MNIST) AI , a później spróbujemy zaimplementować własną sieć, która będzie rozwiązywała inny „popularny” problem (Rozpoznawanie rodzajów Irysów).

Rozpoznawanie obrazu (pisma odręcznego) dla cyfr 0-9
Jak już mówiłem wcześniej jest to jeden z łatwiejszych i częściej używanych przykładów. Z tego powodu zazwyczaj w bibliotekach zbiór danych jest już dodawany niejako „z automatu”. Dzięki temu nie musimy przejmować się właściwie niczym, oprócz utworzenia modelu. Lecimy :).
package it.miacz.djl.simpleffn;
import ai.djl.Model;
import ai.djl.basicdataset.cv.classification.Mnist;
import ai.djl.basicmodelzoo.basic.Mlp;
import ai.djl.modality.Classifications;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.ImageFactory;
import ai.djl.modality.cv.util.NDImageUtils;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.Activation;
import ai.djl.nn.Blocks;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.DefaultTrainingConfig;
import ai.djl.training.EasyTrain;
import ai.djl.training.Trainer;
import ai.djl.training.evaluator.Accuracy;
import ai.djl.training.listener.TrainingListener;
import ai.djl.training.loss.Loss;
import ai.djl.training.util.ProgressBar;
import ai.djl.translate.Batchifier;
import ai.djl.translate.TranslateException;
import ai.djl.translate.Translator;
import ai.djl.translate.TranslatorContext;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) throws IOException, TranslateException {
int inputSize = 28*28;
int outputSize = 10;
//region INFO: (GM) These are just some layers. They are not used in this example
SequentialBlock sequentialBlock = new SequentialBlock();
sequentialBlock.add(Blocks.batchFlattenBlock(inputSize));
sequentialBlock.add(Linear.builder().setUnits(128).build());
sequentialBlock.add(Activation::relu);
sequentialBlock.add(Linear.builder().setUnits(64).build());
sequentialBlock.add(Activation::relu);
sequentialBlock.add(Linear.builder().setUnits(outputSize).build());
//endregion
int batchSize = 32;
Mnist mnist = Mnist.builder().setSampling(batchSize, true).build(); //INFO: Pobieranie obrazków, nic specjalnego, ale powinno być wykonywane tylko raz. (GM)
mnist.prepare(new ProgressBar());
Model model = Model.newInstance("mlp"); //INFO: Tworzenie "modelu" sieci neuronowej. MLP - multilayer perceptron. (GM)
model.setBlock(new Mlp(inputSize, outputSize, new int[]{128,64}));
DefaultTrainingConfig config = new DefaultTrainingConfig(Loss.softmaxCrossEntropyLoss())
.addEvaluator(new Accuracy())
.addTrainingListeners(TrainingListener.Defaults.logging());
Trainer trainer = model.newTrainer(config);
trainer.initialize(new Shape(1, inputSize));
int epoch = 2;
EasyTrain.fit(trainer, epoch, mnist, null); //INFO: Uczenie właściwe (GM)
Path modelDir = Paths.get("build/mlp");
Files.createDirectories(modelDir);
model.setProperty("Epoch", String.valueOf(epoch));
model.save(modelDir, "mlp"); //INFO: Zapis modelu do pliku - żeby nie trzeba go było uczyć za każdym razem (GM)
System.out.println(model);
var img = ImageFactory.getInstance().fromUrl("https://resources.djl.ai/images/0.png");
img.getWrappedImage();
Translator<Image, Classifications> translator = new Translator<>() { //INFO: Obiekt translatora, wymagany aby przerobić "obrazek" do porównania na format danych na jakich "model" był uczony. (GM)
@Override
public NDList processInput(TranslatorContext ctx, Image input) {
NDArray array = input.toNDArray(ctx.getNDManager(), Image.Flag.GRAYSCALE);
return new NDList(NDImageUtils.toTensor(array));
}
@Override
public Classifications processOutput(TranslatorContext ctx, NDList list) {
NDArray probabilities = list.singletonOrThrow().softmax(0);
List<String> classNames = IntStream.range(0, outputSize).mapToObj(String::valueOf).collect(Collectors.toList());
return new Classifications(classNames, probabilities);
}
@Override
public Batchifier getBatchifier() {
return Batchifier.STACK;
}
};
var predictor = model.newPredictor(translator);
var classifications = predictor.predict(img);
System.out.println(classifications); //INFO: Wynik klasyfikacji (GM)
}
}
Jak widać na pierwszy rzut oka – kod jest równie chaotyczny co ten, napisany w pythonie (no może nieznacznie mniej). Gotowy projekt możecie znaleźć w moim repozytorium na github.
Teraz, przy pomocy języka java i programowania obiektowego postaram się nieco ten kod „uładnić” :). Na pierwszy rzut wydzielmy może jakąś konfigurację – albo najlepiej dwie 😉
package it.miacz.djl.mnist.example.config;
public record MultiLayerPerceptronConfig(int inputSize,
int outputSize,
int... hiddenLayersSize) {
}
package it.miacz.djl.mnist.example.config;
import ai.djl.training.DefaultTrainingConfig;
import ai.djl.training.evaluator.Evaluator;
import ai.djl.training.listener.TrainingListener;
import ai.djl.training.loss.Loss;
import lombok.Getter;
public class MyMlpTrainingConfig extends DefaultTrainingConfig {
@Getter
private final int numberOfEpochs;
public MyMlpTrainingConfig(Loss loss, Evaluator evaluator, TrainingListener[] trainingListeners, int numberOfEpochs) {
super(loss);
this.addEvaluator(evaluator);
this.addTrainingListeners(trainingListeners);
this.numberOfEpochs = numberOfEpochs;
}
}
MultiLayerPerceptronConfig trzyma wszystkie dane potrzebne do utworzenia wielowarstwowego perceptronu – rozmiar wejściowy, wyjściowy i rozmiary kolejnych warstw. MyMlpTrainingConfig rozszerza wcześniej wykorzystaną klasę DefaultTrainingConfig i przy użyciu DI przyjmuje parametry, które wcześniej były ustawiane w łańcuchu. Dodatkowo przetrzymuje oczekiwaną przez nas liczbę epok treningu. Przyjrzyjmy się modelowi i translatorowi 🙂
package it.miacz.djl.mnist.example;
import ai.djl.Model;
import ai.djl.basicmodelzoo.basic.Mlp;
import ai.djl.modality.Classifications;
import ai.djl.modality.cv.Image;
import ai.djl.ndarray.types.Shape;
import ai.djl.training.EasyTrain;
import ai.djl.training.Trainer;
import ai.djl.training.dataset.Dataset;
import ai.djl.translate.TranslateException;
import ai.djl.translate.Translator;
import it.miacz.djl.mnist.example.config.MultiLayerPerceptronConfig;
import it.miacz.djl.mnist.example.config.MyMlpTrainingConfig;
import lombok.Getter;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class MyMlpModel {
private final MultiLayerPerceptronConfig multiLayerPerceptronConfig;
@Getter
private final Model model;
public MyMlpModel(MultiLayerPerceptronConfig multiLayerPerceptronConfig) {
this.multiLayerPerceptronConfig = multiLayerPerceptronConfig;
this.model = Model.newInstance("mlp");
this.model.setBlock(new Mlp(multiLayerPerceptronConfig.inputSize(), multiLayerPerceptronConfig.outputSize(), multiLayerPerceptronConfig.hiddenLayersSize()));
}
public void fit(MyMlpTrainingConfig trainingConfig, Dataset trainingDataset, Dataset validatingDataset) throws TranslateException, IOException {
model.setProperty("Epochs", String.valueOf(trainingConfig.getNumberOfEpochs()));
Trainer trainer = getModel().newTrainer(trainingConfig);
trainer.initialize(new Shape(1, multiLayerPerceptronConfig.inputSize()));
EasyTrain.fit(trainer, trainingConfig.getNumberOfEpochs(), trainingDataset, validatingDataset);
}
public void save(String path) throws IOException {
Path modelDir = Paths.get(path);
Files.createDirectories(modelDir);
model.save(modelDir, model.getName());
System.out.println(model);
}
public Classifications predict(Translator<Image, Classifications> translator, Image img) throws TranslateException {
try(var predictor = getModel().newPredictor(translator)) {
return predictor.predict(img);
}
}
}
package it.miacz.djl.mnist.example;
import ai.djl.modality.Classifications;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.util.NDImageUtils;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.translate.Batchifier;
import ai.djl.translate.Translator;
import ai.djl.translate.TranslatorContext;
import it.miacz.djl.mnist.example.config.MultiLayerPerceptronConfig;
import lombok.RequiredArgsConstructor;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
@RequiredArgsConstructor
public class SimpleImageDataTranslator implements Translator<Image, Classifications> {
private final MultiLayerPerceptronConfig multiLayerPerceptronConfig;
@Override
public NDList processInput(TranslatorContext ctx, Image input) {
NDArray array = input.toNDArray(ctx.getNDManager(), Image.Flag.GRAYSCALE);
return new NDList(NDImageUtils.toTensor(array));
}
@Override
public Classifications processOutput(TranslatorContext ctx, NDList list) {
NDArray probabilities = list.singletonOrThrow().softmax(0);
List<String> classNames = IntStream.range(0, multiLayerPerceptronConfig.outputSize()).mapToObj(String::valueOf).collect(Collectors.toList());
return new Classifications(classNames, probabilities);
}
@Override
public Batchifier getBatchifier() {
return Batchifier.STACK;
}
}
Do klasy MyMlpModel przenieśliśmy odpowiedzialność za utworzenie modelu, trening, zapis oraz predykcję (nie chciało mi się już pisać wczytywania ;)) . Wcześniejszą klasę anonimową zastąpiliśmy oddzielną definicją w postaci SimpleImageDataTranslator. Dzięki takiemu podziałowi (nawet mimo, że MyMlpModel agreguje kilka odpowiedzialności) podział odpowiedzialności jest dość jasny i przejrzysty. Zostało przygotowanie danych i wywołanie treningu / predykcji. To już klasa Main 😉
package it.miacz.djl.mnist.example;
import ai.djl.basicdataset.cv.classification.Mnist;
import ai.djl.modality.Classifications;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.ImageFactory;
import ai.djl.training.evaluator.Accuracy;
import ai.djl.training.listener.TrainingListener;
import ai.djl.training.loss.Loss;
import ai.djl.training.util.ProgressBar;
import ai.djl.translate.TranslateException;
import ai.djl.translate.Translator;
import it.miacz.djl.mnist.example.config.MultiLayerPerceptronConfig;
import it.miacz.djl.mnist.example.config.MyMlpTrainingConfig;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException, TranslateException {
var singleImageWidth = 28;
var singleImageHeight = 28;
var numberOfClasses = 10;
int numberOfEpochs = 2;
MultiLayerPerceptronConfig multiLayerPerceptronConfig = new MultiLayerPerceptronConfig(singleImageWidth*singleImageHeight, numberOfClasses, 128, 64);
MyMlpModel myMlpModel = new MyMlpModel(multiLayerPerceptronConfig);
MyMlpTrainingConfig trainingConfig = new MyMlpTrainingConfig(
Loss.softmaxCrossEntropyLoss(),
new Accuracy(),
TrainingListener.Defaults.logging(),
numberOfEpochs);
int batchSize = 32;
Mnist mnist = prepareDataset(batchSize);
myMlpModel.fit(trainingConfig, mnist, null);
var img = ImageFactory.getInstance().fromUrl("https://resources.djl.ai/images/0.png");
img.getWrappedImage();
Translator<Image, Classifications> translator = new SimpleImageDataTranslator(multiLayerPerceptronConfig);
System.out.println(myMlpModel.predict(translator, img));
}
private static Mnist prepareDataset(int batchSize) throws IOException {
Mnist mnist = Mnist.builder().setSampling(batchSize, true).build();
mnist.prepare(new ProgressBar());
return mnist;
}
}
Oczywiście konfiguracja mogłaby być odczytana z linii komend, z kafki lub z pliku 🙂 Byłoby to równie dobre i nie zajmowało miejsca w kodzie metody main 😉 Wydzieliłem jeszcze metodę statyczną prepareDataset – tylko po to, żeby było nieco czyściej.
Cały kod projektu wraz z plikiem pom.xml oraz testami jednostkowymi możecie znaleźć tutaj, a w następnym artykule pokażę jak bez wykorzystania gotowego Mlp stworzyć własną sieć z wybranymi typami warstw ukrytych.
Sorry, że to tyle trwało ale ostatnio jest gorący okres i nie ma kiedy taczki załadować 🙂